Sesión 1 Analisis de datos con R
En este primer módulo aprenderemos a usar R para análisis de datos.
¿Qué es R?
- R es un lenguaje de programación y un ambiente de cómputo estadístico
- R es software libre (no dice qué puedes o no hacer con el software), de código abierto (todo el código de R se puede inspeccionar - y se inspecciona).
- Cuando instalamos R, instala la base de R. Mucha de la funcionalidad adicional está en paquetes (conjunto de funciones y datos documentados) que la comunidad contribuye.
¿Por qué R?
- R funciona en casi todas las plataformas (Mac, Windows, Linux).
- R está pensado y es eficiente para las tareas usuales de análisis.
- R es un lenguaje de programación completo.
- R promueve la investigación reproducible.
- R está actualizado gracias a que tiene una activa comunidad. Solo en CRAN hay más de \(15,000\) paquetes (funcionalidad adicional de R creadas creada por la comunidad).
- R se puede combinar con otras herramientas (sql, spark, python,…).
- R tiene capacidades gráficas muy sofisticadas.
- R es popular (Descargas de paquetes R).
R: primeros pasos
Para comenzar se debe descargar R, esta descarga incluye R básico y un editor de textos para escribir código. Después de descargar R se recomienda descargar RStudio (gratis y libre).
Rstudio es un ambiente de desarrollo integrado para R: incluye una consola, un editor de texto y un conjunto de herramientas para administrar el espacio de trabajo cuando se utiliza R.
Rstudio funciona como aplicación usual que se puede instalar. Pero también funciona como aplicación web, donde R corre en un servidor, y nosotros tenemos acceso a través de un browser como Chrome o Safari. Esta es una manera buena de correr R, pues
- Tenemos acceso a máquinas más grandes
- Es más fácil garantizar reproducibilidad, y es más fácil compartir resultados
- Menos dificultades para instalar paquetes de R
Ahora probamos usar rstudio cloud, donde haremos unos cálculos simples en R.
R en análisis de datos
El estándar científico para contestar preguntas o tomar decisiones es uno que se basa en el análisis de datos. Aquí consideramos técnicas cuantitativas: recolectar, organizar, entender, interpretar y extraer información de colecciones de datos predominantemente numéricos. Todas estas tareas son partes del análisis de datos, cuyo proceso podría resumirse con el siguiente diagrama:
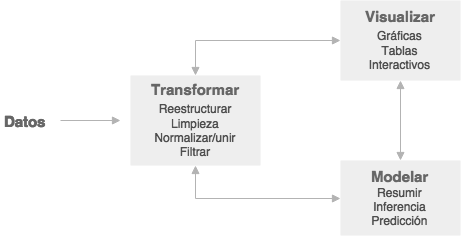
Es importante la forma en que nos movemos dentro de estos procesos en el análisis de datos y en este curso buscamos dar herramientas para facilitar cumplir los siguientes principios:
Reproducibilidad. Debe ser posible reproducir el análisis en todos sus pasos, en cualquier momento.
Claridad. Los pasos del análisis deben estar documentados apropiadamente, de manera que las decisiones importantes puedan ser entendidas y explicadas claramente.
Dedicaremos las primeras sesiones a aprender herramientas básicas para poder movernos agilmente a lo largo de las etapas de análisis utilizando R y nos enfocaremos en los paquetes que forman parte del tidyverse.
Paquetes y el Tidyverse
La mejor manera de usar R para análisis de datos es aprovechando la gran
cantidad de paquetes que aportan funcionalidad adicional. Desde
Rstudio podemos instalar paquetes (Tools - > Install packages o usar la
función install.packages("nombre_paquete")).
Las siguientes lineas instalan los paquetes remotes y readr.
Una vez instalados, podemos cargarlos a nuestra sesión de R mediante library. Por ejemplo, para cargar el
paquete readr hacemos:
## function (file, col_names = TRUE, col_types = NULL, locale = default_locale(),
## na = c("", "NA"), quoted_na = TRUE, quote = "\"", comment = "",
## trim_ws = TRUE, skip = 0, n_max = Inf, guess_max = min(1000,
## n_max), progress = show_progress(), skip_empty_rows = TRUE)
## {
## tokenizer <- tokenizer_csv(na = na, quoted_na = quoted_na,
## quote = quote, comment = comment, trim_ws = trim_ws,
## skip_empty_rows = skip_empty_rows)
## read_delimited(file, tokenizer, col_names = col_names, col_types = col_types,
## locale = locale, skip = skip, skip_empty_rows = skip_empty_rows,
## comment = comment, n_max = n_max, guess_max = guess_max,
## progress = progress)
## }
## <bytecode: 0x7fb1f5a7f640>
## <environment: namespace:readr>read_csv es una función que aporta el paquete readr, que a su vez está incluido en el tidyverse.
El paquete de arriba se instaló de CRAN, pero podemos instalar paquetes que están en otros repositorios (por ejemplo BioConductor) o paquetes que están en GitHub.
Los paquetes se instalan una sola vez, sin embargo, se deben cargar
(ejecutar library(readr)) en cada sesión de R que los ocupemos.
En estas notas utilizaremos la colección de paquetes incluídos en el tidyverse. Estos paquetes de R están diseñados para ciencia de datos, y para funcionar juntos como parte de un flujo de trabajo.
La siguiente imagen tomada de Why the tidyverse (Joseph Rickert) indica que paquetes del tidyverse se utilizan para cada etapa del análisis de datos.
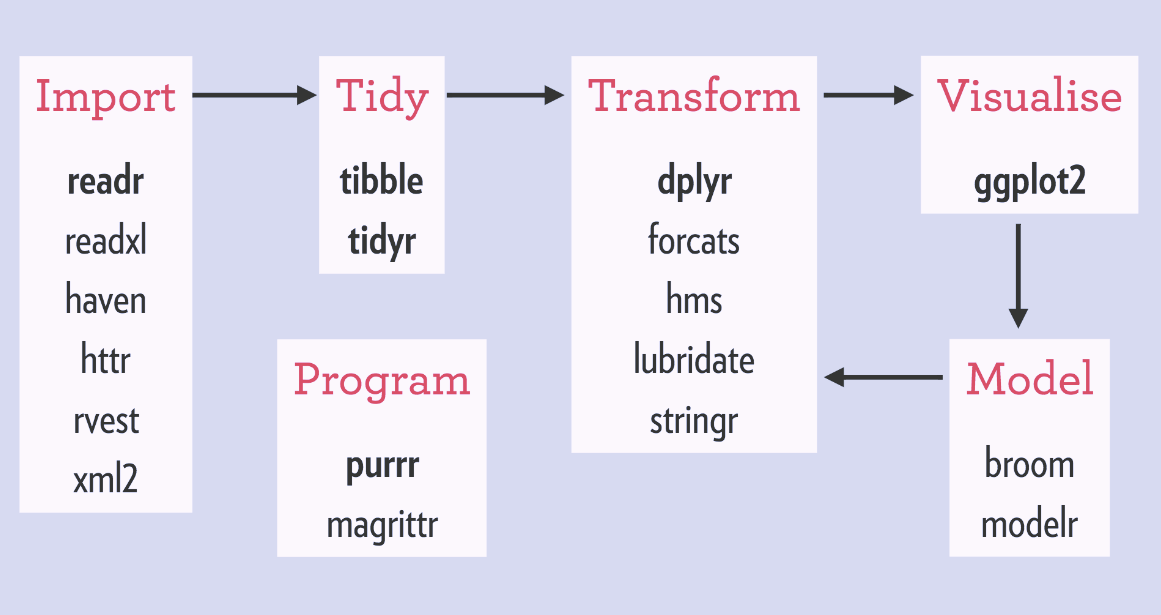
Recursos
Existen muchos recursos gratuitos para aprender R, y resolver nuestras dudas:
- Buscar ayuda: Google, StackOverflow o RStudio Community.
- Para aprender más sobre un paquete o una función pueden visitar Rdocumentation.org.
- La referencia principal de estas notas es el libro R for Data Science
de Hadley Wickham.
- RStudio tiene una Lista de recursos en línea.
- Para aprender programación avanzada en R, el libro gratuito
Advanced R de Hadley Wickham es una buena referencia.
En particular es conveniente leer la guía de estilo (para todos: principiantes, intermedios y avanzados).
- Para mantenerse al tanto de las noticias de la comunidad de R pueden seguir
#rstats en Twitter.
- Para aprovechar la funcionalidad de RStudio.
